How to imagine active learning?
Whenever I hear the term "active learning," I often think of intelligence as constantly evolving... This is somewhat true, but to be precise, it is rather a popular approach to "supervised learning."
In "supervised learning," the "learner," or model, develops on a pre-prepared training dataset. "Active learning" comes into play when our model also participates in the creation of this training data, potentially collaborating with us.
You know that feeling when you're knee-deep in data, and you've got a million labels to assign? Yeah, that's the problem machine learning faces every day. It's like trying to teach a toddler the alphabet with only a handful of letters – it just doesn't stick.
Recently, I came across an article written by Bloomberg about the importance of data labeling, or in other words, data annotation.
Enter active learning. It's the secret sauce that makes machine learning models learn faster, smarter, and with less of that soul-sucking manual labor.
Imagine this: your AI model is like a curious kid, but instead of asking "Why?" it asks "What's this?" It points at a data point and says, "Is this a cat or a dog?"

You, the data expert, give the AI the answer. And guess what? It uses that information to make smarter guesses about other data points.
This is the magic of active learning.
Here's the thing: active learning isn't just about saving time; it's about getting the best results.
Think of it like this:
- Passive learning is like throwing a bunch of pebbles at a target – some might hit, but most will miss.
- Active learning is like using a laser pointer – it precisely targets the most valuable data points, maximizing your chances of hitting the bullseye.

Cycles of labelling and training
If you're interested in learning more about "active learning," read on, because I'd like to present a flowchart that will give you a better idea of what it's all about.
At Lexunit, we actively apply artificial intelligence to business problems, and while the topic of active learning was often not explicitly addressed, common sense always dictated that we should still engage with it.
When creating an artificial intelligence model, the question always arises as to how we can represent the problem with data in a way that leads to a robust solution. This is where we can run into fundamental problems, such as an incomplete representation of the problem or an overrepresentation of a particular type of instance in the dataset. In such cases, this will be reflected in the output of the trained model. We could delve deeper into this topic, but I'd rather present a high-level flowchart to make the process easier to visualize. I took the flowchart from a smart Youtube video that talks about active learning in machine learning.
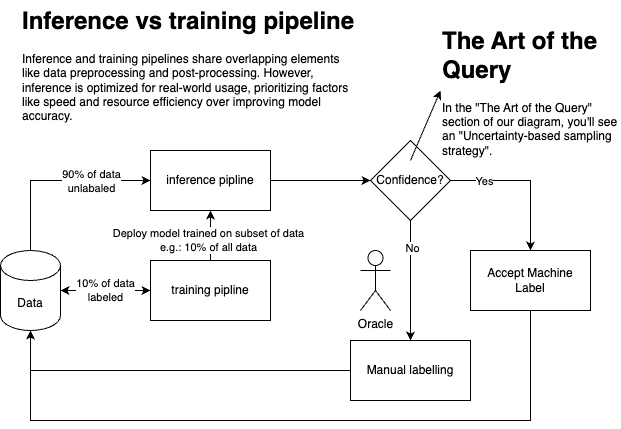
The central question surrounding the diagram is: how can I reduce the time spent labeling data without compromising the quality of the model's output resulting from training? As it turns out, human involvement is necessary in the process, often referred to as the "Oracle." The "Oracle" provides the "ground truth" data. The goal is for the "Oracle" to focus on labeling data that has the most significant impact on the performance of the trained model.
As seen in the diagram, this is not a one-time event but rather an iterative process of data labeling (Oracle's work, AKA: human in the loop) together with supervised training on it. This means that throughout the lifecycle, the training dataset is enriched and refined, allowing the model to be retrained periodically. The scheduling and granularity of this process can be customized, initiated manually or automatically, and so on. The key is that the training dataset, along with the model and its data labeling capabilities, improves throughout the process.
By now, there is a wealth of literature available on active learning. At Lexunit, we organically realized its necessity through our own reasoning, as when intelligence needs to produce results on a random, unstructured dataset, it becomes crucial how the training data is assembled... and of course, how to label it when dealing with vast amount of data.
We first encountered programmatic labeling in 2017 when Snorkel.AI published its research paper on "weak supervised learning." This has significantly accelerated the development of systems that require a large amount of training data. If you're interested, read their accompanying publication. This programmatic approach utilizes human involvement in the labeling process differently and is just another related topic to the "supervised learning" large data problem. Watch out, Snorkel programmatic labeling approach and "active learning" have overlapping areas, but they are different paradigms.
State of active learning techniques: https://arxiv.org/abs/2405.00334
Weak supervised learning: https://arxiv.org/pdf/1711.10160
So, what are the secrets to unlocking the power of active learning?
Here's the breakdown:
The Art of the Query
Active learning isn't just about randomly picking data points. It's about using smart strategies to select the most informative examples for labeling.
- Uncertainty-based strategies: Focus on the data points the model is most unsure about. Think of it as the "I don't know" moments that drive the model's learning.
- Representative-based strategies: Aim to select a diverse set of data points that represent the entire data pool. Imagine it as gathering a group of people from different backgrounds to get a well-rounded perspective.
- Influence-based strategies: Target data points that will have the biggest impact on the model's overall performance. It's like picking the key players who will make the biggest difference in a team's success.
- Bayesian strategies: Leverage the power of probability to select data points that will most effectively improve the model's beliefs. Think of it as making the model more confident in its understanding of the data.
The Deep Learning Connection
Active learning isn't just for traditional machine learning; it's also a game-changer for deep learning models.
- Large Language Models (LLMs): Active learning helps fine-tune these powerful models with minimal labeled data.
- Convolutional Neural Networks (CNNs): Active learning helps extract the most valuable features from images, reducing the need for extensive hand-labeling.
- Graph Neural Networks (GNNs): Active learning tackles the challenge of labeling nodes in complex networks, enabling more efficient knowledge discovery.
The Power of Hybrid Strategies
The best active learning strategies often combine multiple approaches. Imagine it like a well-rounded team, where each player brings unique strengths to the table.

- Uncertainty and diversity: Selecting both the most uncertain data points and a diverse representation of the data pool.
- Uncertainty and influence: Choosing data points that are both uncertain and likely to have a significant impact on the model's performance.
The bottom line: Active learning is a game changer for anyone working with machine learning. It's the key to unlocking the full potential of your AI models, saving time, and achieving the best possible results. So, ditch the manual labeling drudgery and embrace the future of AI – the active learning revolution is here!
Please feel free to leave us a message!